
游戏图形批量渲染及优化
Unity动态合批技术
试想一个场景:一场激烈的战斗中,双方射出的箭矢飞行在空中,数量很多,材质也相同;但因为都在运动状态,所以无法进行静态合批;倘若一个一个的绘制这些箭矢,则会产生非常多次绘制命令的调用。
让人热血沸腾的一场激战
对于这些模型简单、材质相同、但处在运动状态下的物体,有没有适合的批处理策略呢?有吧,动态合批就是为了解决这样的问题。
动态合批没有像静态合批打包时的预处理阶段,它只会在程序运行时发生。动态合批会在每次绘制前,先将可以合批的对象“整理”在一起,然后将这些单位的网格信息进行“合并”,接着仅向GPU发送一次绘制命令,就可以完成它们整体的绘制。
动态合批比较简单,但有两点仍然需要注意:
1、合批并非是在绘制前“合并网格“
动态合批不会在绘制前创建新的网格,它只是将可以参与合批单位的顶点属性,连续填充到一块顶点和索引缓冲区中,让GPU认为它们是一个整体。
在Unity中,引擎已自动为每种可以动态合批的渲染器分配了其类型公用的顶点和索引缓冲区,所以动态合批不会频繁的创建顶点和索引缓冲区。
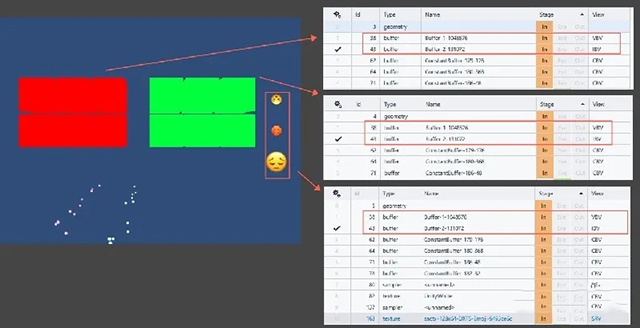
MeshRenderer、SpriteRenderer动态合批时使用了公用的顶点、索引缓冲区
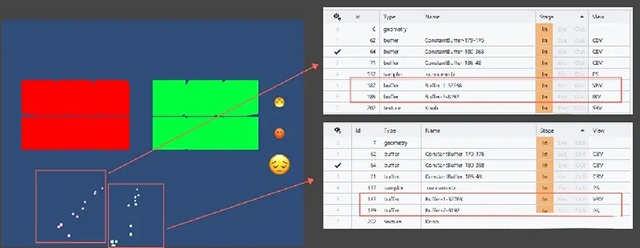
ParticleSystemRenderer动态合批时使用了与MeshRenderer不同的公用顶点、索引缓冲区
2、合批前会先处理每个顶点的顶点属性
在向顶点和索引缓冲区内填充数据前,引擎会处理被合批网格的每个顶点信息,将其空间变换到世界坐标系下。
这是因为这些对象可能都不属于相同的父节点,因此无法对其进行统一的空间转换(本地到世界),需要在送进渲染管线前将每个顶点的坐标转换为世界坐标系下的坐标(所以Unity中,合并后对象的顶点着色器内被传入的M矩阵,都是单位矩阵)。
| Unity动态合批的条件
相对于上述看起来有点厉害但是本质上无用的知识而言,了解动态合批规则其实更为重要。比如:
●材质球相同;
●Mesh顶点数量不能超过300以及顶点属性不能超过900;
●缩放不能为负值(x、y、z向量的乘积不能为负)等。
但我个人认为你不需要记住每一个条件,除了上述相对重要些的条件外,其余的可以通过FrameDebugger中提示的合批失败原因,来反向了解合批条件。
| 与静态合批的差别
动态合批与静态合批最大的差别在于:
1、动态合批不会创建常驻内存的“合并后网格”,也就是说它不会在运行时造成内存的显著增长,也不会影响打包时的包体大小;
2、动态合批在绘制前会先将顶点转换到世界坐标系下,然后再填充进顶点、索引缓冲区;静态合批后子网格不接受任何变换操作,仅手动合批后的Root节点可被操作,因此静态合批的顶点、索引缓冲区中的信息不会被修改(Root的变换信息则会通过Constant Buffer传入);
3、因为2的原因,动态合批的主要开销在于遍历顶点进行空间变换时的对CPU性能的开销;静态合批没有这个操作,所以也没有这个开销;
4、动态合批使用根据渲染器类型分配的公共缓冲区,而静态合批使用自己专用的缓冲区。
虽然在Unity中,存在多种可以被动态合批的渲染器类型,而且其合批规则可能也略有不同;但我个人认为其原理应该是相似的,因此这里就不针对每种渲染器做单独的测试和说明了,后面有必要、有机会、有缘分的话,再仔细了解吧。
Unity实例化渲染
当我们想要呈现这样的场景:一片茂密的森林、广阔的草原或崎岖的山路时,会发现在这些场景中存在大量重复性元素:树木、草和岩石。
仙境怕是也不过如此吧
它们都使用了相同的模型,或者模型的种类很少,比如:树可能只有几种;但为了做出差异化,它们的颜色略有不同,高低参差不齐,当然位置也各不相同。
使用静态合批来处理它们(假设它们都没有动画),是不合适的。因为数量太多(林子大了,多少树都有),所以合并后的网格体积可能非常大,这会引起内存的增加;而且,这个合并后的网格还是由大量重复网格组成的,不划算。
使用动态合批来处理他们,虽然不会“合并”网格,但是仍然需要在渲染前遍历所有顶点,进行空间变换的操作;虽然单颗树、石头的顶点数量可能不多,但由于数量很多,所以也会在一定程度上增加CPU性能的开销,没必要。
那么,对于场景中这些模型重复、数量多的渲染需求,有没有适合的批处理策略呢?有吧,实例化渲染就是为了解决这样的问题。
| 简述工作原理
实例化渲染,是通过调用“特殊”的渲染接口,由GPU完成的“批处理”。
它与传统的渲染方式相比,最大的差别在于:调用渲染命令时需要告知GPU这次渲染的次数(绘制N个)。当GPU接到这个命令时,就会连续绘制N个物体到我们的屏幕上,其效率远高于连续调用N次传统渲染命令的和。
举个例子,假设希望在屏幕上绘制出两个颜色、位置均不同的箱子。如果使用传统的渲染,则需要调用两次渲染命令(DrawCall = 2),分别为:画一个红箱子 和 画一个绿箱子。
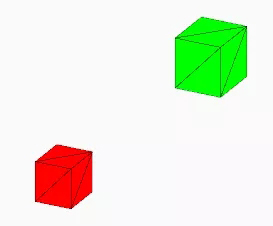
两个颜色、位置各异的箱子
如果使用实例化渲染,则只需要调用一次渲染命令(DrawCall = 1),并且附带一个参数2(表示绘制两个)即可。
当然,如果只是这样,那GPU就会把两个箱子画在相同的位置上。所以我们还需要告诉GPU两个箱子各自的位置(其实是转换矩阵)以及颜色。
这个位置和颜色我们会按照数组的方式传递给GPU,大概这个样子吧:
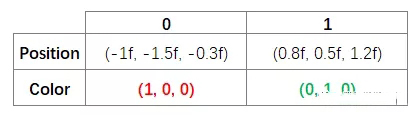
分别传递保存位置和颜色的数组
那接下来GPU在进行渲染时,就会在渲染每一个箱子的时候,根据当前箱子的索引(第几个),拿到正确的属性(位置、颜色)来进行绘制了。
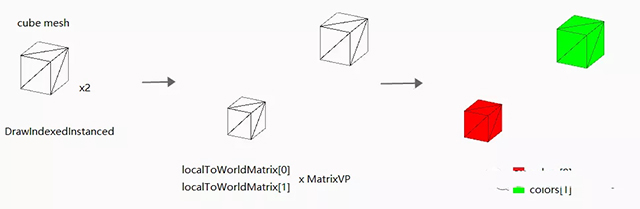
一个简单的实例化渲染流程
| Unity是如何处理实例化的
我们通过一个简单的场景,来看一下Unity为实例化渲染做了什么。
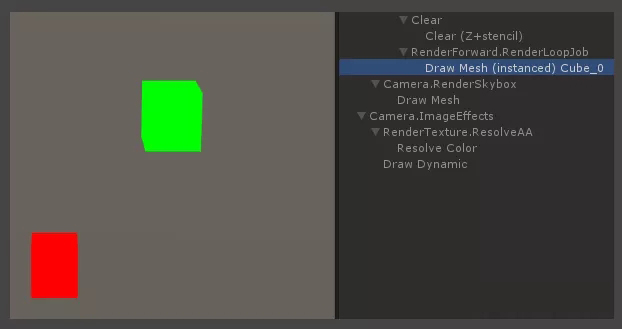
实例化渲染两个彩色箱子

颜色属性通过MaterialPropertyBlock传入
通过GPA观察Unity做了什么。

GPA中的VertexBuffer和IndexBuffer中的信息
注:Unity默认Cube网格,包含24个顶点和36个索引。
顶点缓冲区Size = (Position(float3)
Normal(float3)
Tangent(float4)
TexCoord(float2)
TexCoord1(float2)) x 24 = 1344Byte
索引缓冲区Size = Index(ushort) x 36 = 72Byte
可见,顶点、索引缓冲区内,确实只有一个网格的数据。
那么GPU如何判断每个Cube的绘制位置,及其颜色呢?
结合引擎为Dx平台生成的shader(我的测试环境使用的是Pc),可以很容易找到对应的数据。
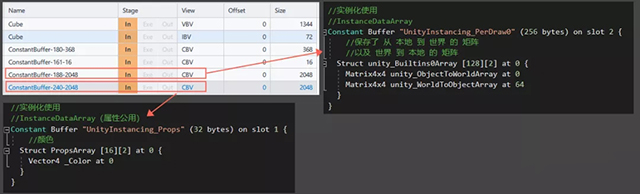
转换矩阵及颜色被分别填入Constant Buffer中
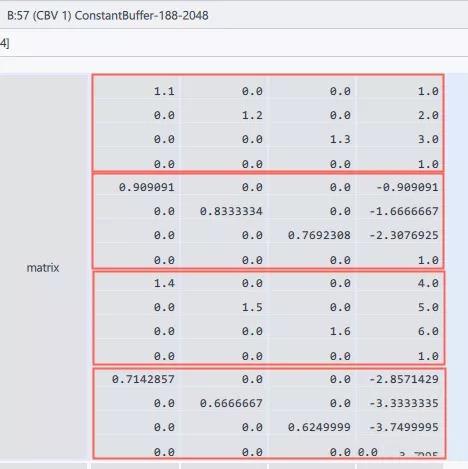
Constant Buffer中的矩阵(Dx为行向量)
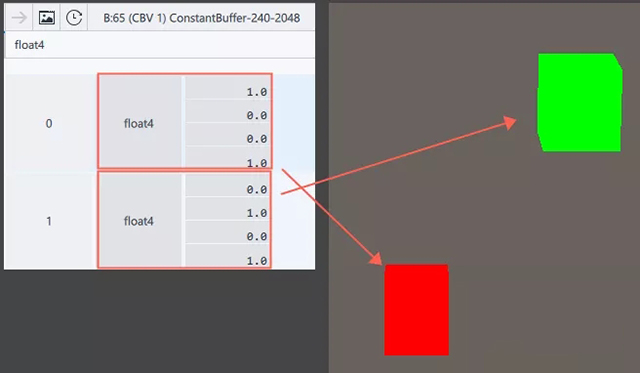
Constant Buffer中的属性(颜色)
可见,渲染时GPU可以通过当前实例化单位的索引,从Buffer中获取到对应的属性,完成正确的绘制。
| Unity中启用实例化渲染
当然,相比于上述无用的知识点,如何在Unity中使用实例化渲染可能更为重要。
在Unity中可以通过自动或手动的方式,启用实例化渲染。
自动启用实例化渲染
使用支持实例化渲染的Shader,并勾选材质球上的启用开关,Unity便会对满足条件的物体,自动开启实例化渲染。
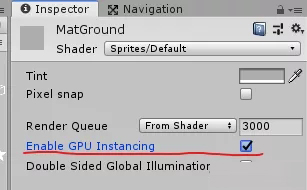
有这个选项即表示该Shader支持实例化渲染
自定义Shader
如果你希望自己的Shader也支持实例化渲染,应重点注意以下内容:
pragma multi_compile_instancing
启用实例化渲染(材质球上将出现启用实例化的勾选框);
UNITY_VERTEX_INPUT_INSTANCE_ID
在a2v及v2f的结构中定义实例化索引下标(SV_InstanceID ),也就是当前渲染单位的索引,用于从Constant Buffer中提取正确的属性(做显示差异化用);
UNITY_INSTANCING_BUFFER_START ~ END
在这个起止区域内定义属性,才能在着色器中正确的根据索引提取出当前渲染单位所对应的属性;
UNITY_SETUP_INSTANCE_ID
定义在着色器的起始位置,使顶点着色器(或片段着色器)可以正确的访问到实例化单位的索引;
UNITY_ACCESS_INSTANCED_PROP
根据索引访问到这个单位对应的属性,如上面例子中每个箱子的颜色属性。
这里只是简述一些相对重要的内容(凑些字数),官方文档中有更详细内容,建议优先了解。
手动实例化渲染
使用 Graphics.DrawMeshInstanced 和 Graphics.DrawMeshInstancedIndirect 来手动执行 GPU 实例化,详见官方文档中的解释,这里就不再赘述了。
| 实例化渲染的使用要求
并非所有设备都可以使用实例化渲染。
在Unity官方文档中,列举了各平台支持实例化渲染的最低要求。
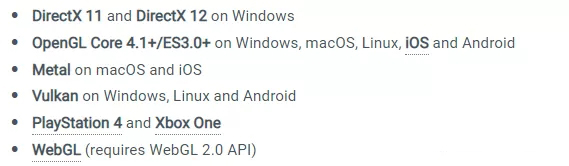
官方文档中对支持实例化渲染的最低API要求
当然,我们也可以通过引擎中SystemInfo.supportsInstancing属性来判断环境是否支持实例化渲染。
那支持实例化渲染的机器占比大概是多少呢?由于国内大多数游戏公司都是以手游项目糊口。所以开发者可能会更多关注其在安卓平台上的情况。
根据Android开发者的官方数据显示,截至2020年8月30日,约88%的活跃安卓设备,都已经支持实例化渲染,所以基本上可以放心使用。
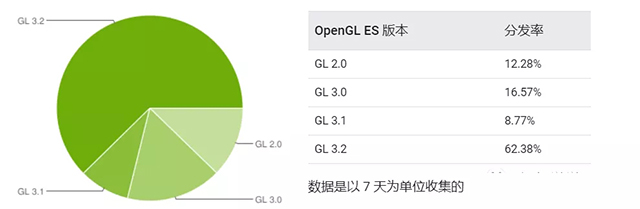
android开发者官网发布的活跃设备OpenGL ES版本占比信息
| 与静、动态合批的差异
静、动态合批实质上是将可以合批的对象真正的合并成一个大物体后,再通知GPU进行渲染,也就是其顶点索引缓冲区中必须包含全部参与合批对象的顶点信息;因此,可以认为是CPU完成的批处理。
实例化渲染是对网格信息的重复利用,无论最终要渲染出几个单位,其顶点和索引缓冲区内都只有一份数据,可以认为是GPU完成的批处理。
其实这么总结也有点问题,本质上讲:动、静态合批解决的是合批问题,也就是先有大量存在的单位,再通过一些手段合并成为批次;而实例化渲染其实是个复制的事儿,是从少量复制为大量,只是利用了它“可以通过传入属性实现差异化”的特点,在某些条件下达到了与合批相同的效果。
| 简单总结静、动态合批及实例化渲染
无论是静态合批、动态合批或实例化渲染,本质上并无孰优孰劣,它们都只是提高渲染效率的解决方案,也都有自己适合的场景或擅长解决的问题。
转载声明:本文来源于网络,不作任何商业用途。
全部评论


暂无留言,赶紧抢占沙发
热门资讯

专访|王氏教育集团康海威老师:国民手游《王者荣耀》曹操高低模打造者...

什么!参加王座杯能瓜分25000元?先让旺旺哒我康康!...

绘学霸规则玩法大全

实际跟拍丨多名学员用行动告诉你,毕业就等于就业!...

绘学霸订单服务协议V1.1.0

《听雪楼》获20亿播放量的背后,少不了我们有才有颜师姐的鼎力相助!...

原画绘画风格,你知道几种?

CG人物女性盔甲人物角色作品欣赏

关于鼓励举报“第19届王座杯CG大赛”涉嫌抄袭、AI绘图等违规作品的公告...





